Comparisons and Conclusions
Outline
I. How Do Our Models Stack Up in Vegas?
Vegas betting lines have long set the standard for gambling odds in sports. Their 3-Way betting odds for each game in this year's World Cup provide us with baseline predictions to compare our model with.
We hand-coded a dataset that contains Vegas's predictions for all 64 games in the 2018 World Cup, as well as the outcome of those predictions. Interestingly enough, just like to our models, the Vegas model predicted no ties in this year's World Cup. The Vegas model called about 57.8% of the games correctly, as shown below:

This accuracy is slightly better than that of each of our baseline models, and it is slightly higher than what most of our final models were able to achieve. Our Ridge Classification model was the only one that outperformed it on the 64 games that were played in the 2018 World Cup.
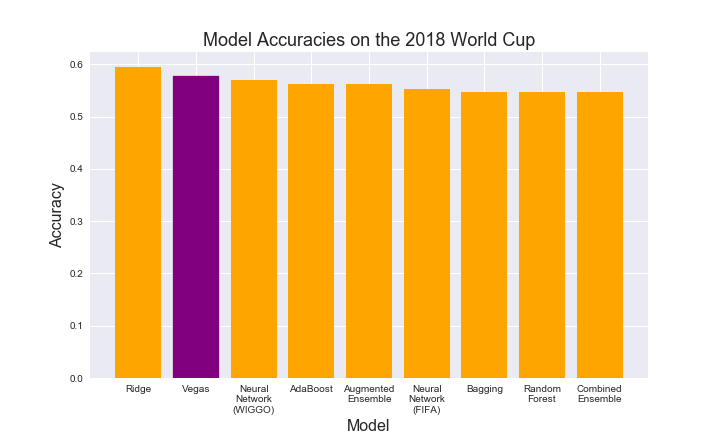
It is important to note that with only 64 games, predicting one more game correctly can increase a model's accuracy by a significant margin. Of the models listed above, the most accurate one only got 3 more games correctly than the worst ones did. Thus, it is still rather uncertain how each of these models would perform in future World Cups.
However, all of our models are at least comparable with the Vegas one. With some fine-tuning, our Neural Network with WIGGO shows signs that it has the potential to beat out Vegas in World Cup prediction.
II. Conclusions
It turns out it's very tough to achieve a high accuracy on World Cup predictions, but it does seem like a good model is able to slightly outperform Vegas predictions. Whether it's able to outperform bookies enough to cover the house cut is still unclear. Here are some other, more actionable insights we gained from our project:
WIGGO seems like a better predictor of match outcomes than FIFA. Although the two systems performed comparably in their predictions, WIGGO has a slight edge on both the training and test sets when it comes to predicting which team will win the match based solely on ranking information. Furthermore, models that included both WIGGO and FIFA seemed to value WIGGO information more highly than FIFA information.
Fatigue metrics did not prove to be valuable predictors. The gains in accuracy we made on the test sets (and even training sets sometimes) by including up to 30 predictors were very small. Models based off nothing other than WIGGO information performed about as well as models that included Distance from Home, Travel Distance, and Time Zone Deltas.
The current optimal strategy is not predicting draws. We thought it was curious that our models rarely, if ever, predicted draws. For example, the Neural Network did not predict a single draw, even though they make up over a quarter of our training set. However, while studying Vegas odds, we found that their strategy also consisted of never predicting draws, so we consider that not predicting draws was not a bug, but rather a feature of our models.
III. Future Research
Since we built this project in a matter of a few weeks, there's still a lot more we could do with it. Here are three avenues we would pursue if we had more time:
Expand our test set to prevent overfitting. Because our analysis focused heavily on the FIFA Ranking, we were limited to only two World Cups worth of data. WIGGO information could in theory be calculated to go back as far as we want, which would give us a better sense for how well our models perform in World Cups, as opposed to how well they performed at the 2018 World Cup specifically. We also considered restricting our training set only to competitive games (excluding friendlies). We think there could be aspects of competitive games that might get lost in all the friendlies in the dataset, but restricting this way would leave us with a smaller sample and almost no cross-confederations game, so there are pros and cons.
Include individual player information. Again, because our analysis focused heavily on ranking systems, we took a fully team-centric approach, when we could have also incorporated information about the specific players on the roster of each country, like the FiveThirtyEight model does. Since there are 736 players at the World Cup, though, such a model could quickly become extremely complex and unruly. But if our goal is to maximize accuracy, it could turn out that that complexity might be worth the trouble.
Build a draw-predicting model. We think this could crack the code to building a very powerful prediction model. As things stand now, our models (and Vegas) abstain from predicting ties as an optimization strategy. However, if we were to build a model that could identify games that are likely to end in ties, we could ensemble it with our current models as a form of gradient boosting. The tie-predicting model removes games it identifies as likely to end in a tie, and then the win-loss predicting models make predictions on the remaining games. If the tie-predicting model is good enough, it could potentially increase overall accuracy from the high 50's into the high 60's or even low 70's. We don't know yet if building a good tie-predicting model is feasible, but we did talk about changing our loss functions to ones used in ordinal classification so that games that are wrongly classified as ties would be penalized less than games that are wrongly classified as a win when the true result was a loss, since a draw is “closer” to a loss, even if they are different classes.
IV. L.E.O.N.
Lizard Exploratory Output Network (L.E.O.N)
Another relatively unexplored prediction model is that of chameleon prediction. Using a chameleon named "Leon," predictions for the 2018 FIFA World Cup were generated based on which of two crickets Leon ate first -- the cricket representing the home team or the cricket representing the away team. Using this revolutionary new technique, a test accuracy of 62.5% was achieved for the 2018 World Cup. Comparing the L.E.O.N. model to the other models in the project, it becomes clear that the predictive power of a chameleon far exceeds that of any computer (see plot below).
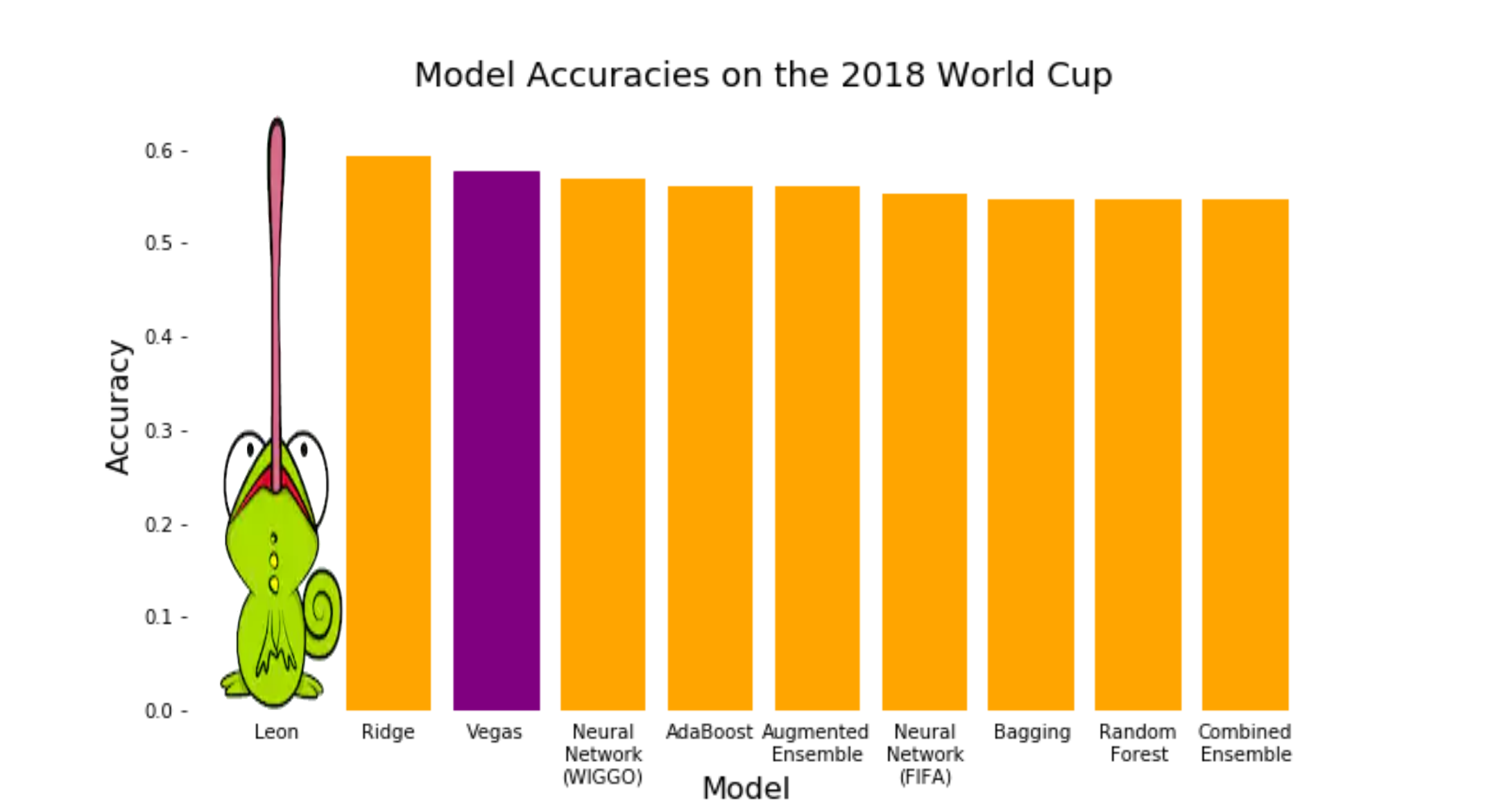
It is therefore recommendable to focus all modelling efforts into finding the single chameleon who will be able to achieve a test accuracy of 100%.